Quote:
Originally Posted by classhandicapper
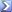
Here's a quick sample of the kind of thing you can do in 5 minutes.
This is Jockey performance for riders that had a minimum of 25 mounts on favorites at AQU, BEL and SAR. This covers about 2 1/2 years. Doing it by rank will take a little longer. Something like this could also obviously be broken up by track, distance, surface, running style etc...
The average for all NYRA jockeys was 2.83.
So anything lower than 2.83 would be positive and anything higher would be negative. You can also see the average odds of the favorites the jockey ride to make an adjustment there.
|
Yup.
That's a good illustration of using the type of analysis being discussed in this thread to come up with a rider rating.
I wanted to add to my previous post and provide some data.
The sample below shows all morning line favorites that have raced at what I consider to be A and B tracks over (roughly) the past three weeks:
Code:
query start: 1/9/2018 10:47:34 AM
query end: 1/9/2018 10:47:35 AM
elapsed time: 1 seconds
Data Window Settings:
Connected to: C:\JCapper\exe\JCapper2.mdb
999 Divisor Odds Cap: None
SQL UDM Plays Report: Hide
SQL: SELECT * FROM STARTERHISTORY
WHERE RANKMLINE=1
AND INSTR('AQU-GGX-GPX-HAW-LRL-PHA-TAM-SAX', TRACK) > 0
AND [DATE] >= #12-17-2017#
AND [DATE] <= #01-08-2018#
ORDER BY [DATE], TRACK, RACE
Data Summary Win Place Show
-----------------------------------------------------
Mutuel Totals 1043.50 1094.70 1080.40
Bet -1258.00 -1258.00 -1258.00
-----------------------------------------------------
P/L -214.50 -163.30 -177.60
Wins 196 333 411
Plays 629 629 629
PCT .3116 .5294 .6534
ROI 0.8295 0.8702 0.8588
Avg Mut 5.32 3.29 2.63
Nothing Earth shattering there. (The above results are about what you'd expect from morning line favorites.)
I recently wrote an algorithm (involving a little bit of AI) that calculates Cumulative Probability or F(x) for each rider given the situation he or she finds himself or herself in.
Admittedly, classifying individual rider situations is something subjective on my part.
That said, the algorithm is programmed to analyze the attributes for each mount, and from there classify that mount as belonging to a basic category such as inside speed, inside closer, middle post speed, middle post closer, outside speed, or outside closer.
From there the algorithm is programmed to pull each rider's like mounts from the database and calculate F(x) -- with the resulting F(x) representing actual performance vs. expected performance over all the times the rider was asked to perform that specific task... for example, ride an inside closer in a sprint race on the dirt at today's track.
All of that said, here is the above sample broken out by rank for Rider (Fx) as described above:
Code:
By: SQL-F01 Rank -- F(x) for Rider, given the situation
Rank P/L Bet Roi Wins Plays Pct Impact AvgMut
----------------------------------------------------------------------------------
1 48.60 190.00 1.2558 43 95 .4526 1.4526 5.55
2 -56.80 152.00 0.6263 19 76 .2500 0.8023 5.01
3 -4.50 126.00 0.9643 22 63 .3492 1.1207 5.52
4 -56.20 130.00 0.5677 15 65 .2308 0.7406 4.92
5 -46.60 170.00 0.7259 23 85 .2706 0.8684 5.37
6 -7.00 142.00 0.9507 26 71 .3662 1.1752 5.19
7 -35.80 122.00 0.7066 15 61 .2459 0.7891 5.75
8 -35.00 104.00 0.6635 13 52 .2500 0.8023 5.31
9 -32.00 68.00 0.5294 8 34 .2353 0.7551 4.50
10 20.20 32.00 1.6313 10 16 .6250 2.0057 5.22
11 -9.80 14.00 0.3000 1 7 .1429 0.4585 4.20
12 0.40 8.00 1.0500 1 4 .2500 0.8023 8.40
And here is the above sample broken out by numeric value for Rider (Fx) as described above:
Code:
By: SQL-F01 Numeric Value -- F(x) for Rider, given the situation
>=Min < Max P/L Bet Roi Wins Plays Pct Impact
--------------------------------------------------------------------------------------
-99.0000 0.0000 0.00 0.00 0.0000 0 0 .0000 0.0000
0.0000 0.0500 -3.80 160.00 0.9763 32 80 .4000 1.2837
0.0500 0.1000 -15.70 128.00 0.8773 22 64 .3438 1.1032
0.1000 0.1500 -76.10 170.00 0.5524 18 85 .2118 0.6796
0.1500 0.2000 -14.60 82.00 0.8220 11 41 .2683 0.8610
0.2000 0.2500 -26.60 64.00 0.5844 7 32 .2188 0.7020
0.2500 0.3000 -8.70 76.00 0.8855 14 38 .3684 1.1823
0.3000 0.3500 9.20 74.00 1.1243 12 37 .3243 1.0408
0.3500 0.4000 -15.80 36.00 0.5611 4 18 .2222 0.7132
0.4000 0.4500 -17.20 32.00 0.4625 2 16 .1250 0.4011
0.4500 0.5000 -12.40 42.00 0.7048 6 21 .2857 0.9169
0.5000 0.5500 -16.80 96.00 0.8250 17 48 .3542 1.1366
0.5500 0.6000 -4.00 30.00 0.8667 5 15 .3333 1.0697
0.6000 0.6500 -24.60 40.00 0.3850 3 20 .1500 0.4814
0.6500 0.7000 -7.60 20.00 0.6200 2 10 .2000 0.6418
0.7000 0.7500 -6.80 14.00 0.5143 2 7 .2857 0.9169
0.7500 0.8000 -20.20 24.00 0.1583 1 12 .0833 0.2674
0.8000 0.8500 -11.80 22.00 0.4636 2 11 .1818 0.5835
0.8500 0.9000 1.30 20.00 1.0650 4 10 .4000 1.2837
0.9000 9999.0000 57.70 128.00 1.4508 32 64 .5000 1.6046
Note the outperformance by the rank=1 mounts for Rider F(x).
Also note the outperformance at the extreme edges of the Rider F(x) numeric value distribution. In theory, any F(x) value over 0.50 represents outperformance.
Yet, in this sample, the strongest outperformance occurred when F(x) was greater than or equal to 0.85.
I'm guessing outperformance only when F(x) is greater than or equal to 0.85 may turn out to be the result of small sample noise. (My gut tells me a larger sample is needed.)
That said, this is the first sample I've generated using this technique and the results are promising (at least so far.)
I also wanted to touch on outpeformance at the other edge of the sample -- specifically when F(x) is equal to zero.
A closer look at the data reveals this part of the sample is populated by riders who have a small number of mounts in the situation they are being queried for.
For example: If a rider only has three mounts as a closer with a far outside post in dirt routes at today's track -- and the query results come back as 0 for 3 with an F(x) of 0.00... That 0.00 is probably not a true representation of the rider's ability in that situation.
-jp
.

