Quote:
Originally Posted by steveb
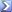
there was at least 8 starters in every race.
the only way you can confidently account for field size if you don't have enough is to standardise or normalise them.
your last sentence does not make sense because lengths come from time, so there would be very strong correlation between the two.
as an indication of that correl, here is something i do every time i add data as a check.
i make 2 files every meeting, here is one that does each race correlation between margin and time.
this enables me to pick up errors....not that it ever happens in hk but it certainly does most other joints.
date/track/racetype/correlation between time&margin/conversion factor
conversion factor is always .16 but because the margin are in increments of .25 then never perfect, but it's the margin that's wrong not the time.
|
The reason I mentioned I was using lengths is that I don't know the exact conversion formula for beaten lengths to time in the US.
In the data I just posted I only displayed finish positions 2-4. That way field size is not much of an issue. If there is any distortion because a handful of fields only had 3-4 horses and others had more I doubt it had a huge impact. It's the horses way in the back of the field that distort beaten lengths averages because they often get eased.
When I studied the data initially, I broke each set out by the field size.
It was by Distance, Surface, Track Condition, Field Size, Finish Position, Beaten lengths for every combination.
I started this project trying to improve some ratings I create for myself. I was looking for a relatively simple formula I could use. The more I looked at the data the more I realized there was no simple solution to what I wanted. So I dropped it. I focused primarily on finish position with field size and beaten lengths being secondary. That worked better. I'm sure I could make the system much better, but it's good enough for my purposes. I always dig into races in a more detailed way than I can program anyway.

